Spacy 101
Table of Contents
notes when following the tutorial https://spacy.io/usage/spacy-101. The tooling itself (SpaCy) is referred throughout this zettelkasten as a sentinel subtree in the machine learning head. Once this has been processed, will also be processing https://course.spacy.io/en/ (Advanced NLP with spaCy) into these notes
1. Overview
1.1. Features available
| Task/Utilisation | Existing Relevant Node |
|---|---|
| Tokenization | Text Representation |
| Part of Speech Tagging | Information Extraction |
| Dependency Parsing | Information Extraction |
| Lemmatization | Text Representation |
| Sentence Boundary Detection | --- |
| Named Entity Recognition | Named Entity Recognition (NER) |
| Entity Linking | Named Entity Disambiguation and Linking (NED and NEL) |
| Similarity | see cosine similarity for one approach |
| Text Classification | Text Classification |
| Training | --- |
| Serialization | Serialization |
1.2. Linguistic annotations
- variety of tooling to gain insights into the grammatical structure of text being analysed.
- word types (part of speech), further categorization eg:- nouns into subjects and objects. same words differentiated via their POS ("google" being a verb or a noun…)
1.3. Trained pipeline
Most of the features work independently but some require loading "trained pipelines". They're composed of the following:
- binary weights for part of speech tagger, dependency parser, and NER
- lexical entries : words and their attributes (spelling, length)
- data files: lemmatization and lookup tables
- word vectors: see Text Representation
- configs: metadata to load the pipeline with appropriate configuration
1.3.1. Loading a pipeline
- trained pipelines are loaded as
Languageobjects - on the first call, the pipeline will be downloaded and installed
- these
Languageobjects are usually named asnlp - when passing text through a pipeline, we receive a processed
Docobject
import spacy nlp = spacy.load('en_core_web_sm') doc = nlp("the quick brown fox jumped over the lazy dog") for token in doc: print(token.text, token.pos_, token.dep_)
- some convenient characteristics of a
Docobject- is an iterable of tokens
- each token has the attributes .text , .pos_ (part of speech) , and .dep_ (dependency relation)
- no information is lost and all text (whitespace, unique characters) will still be accessible in the doc object
- see https://spacy.io/api/token
2. Elaborating
2.1. Tokenization
- see Text Representation
- segmenting text into words, punctuation and other similar discrete structures
- this needs to be done smartly and based on context :- each period isn't a full stop ("U.S.A" for instance should be one token without any punctuations)
- a trained pipeline (Language object usually addressed as nlp) when applied to a text, produces an iterable of tokens.
- first step is splitting with whitespace, after which the splits are processed from left to right with the following checks:
- check if it is an exception
- "don't" => "do" and "n't"
- "U.K." stays the same
- check or splittable suffixes, prefixes and infixes
- commas, periods, hyphens or quotes are candidates for such splits
- anti-clockwise => "anti" and "clockwise"
- check if it is an exception
- each language needs its own set of extensive hard coded data and exception rules that need to be loaded when using that particular trained pipeline.
- for further details and customization options, see :
2.2. Part of speech tags and dependencies
- post tokenization, a
Doccan be parsed and tagged.- the statistical models come into play at this stage.
- linguistic annotations are available as attributes of token objects.
- strings are hashed for efficiency, so defaults are integers:
tok.pos: integer hash of part of speech tagtok.pos_: the part of speech tag (string)tok.dep: integer hash of the dependency tagtok.dep_: the dependency tag as string
- conventions for attributes:
- base word is the integer hash
- _ appended yields the string tag
- a summary of the attributes of a token is as follows:
- text : the original text
- Lemma : base form of the word
- POS : simple part of speech tags in the format mentioned https://universaldependencies.org/u/pos/
- Tag : detailed part-of-speech tags
- Dep : syntactic dependency -> relation between tokens
- shape : capitalization, punctuation and digits (eg: Apple -> Xxxxx, U.K. -> X.X., 3 -> d)
- is alpha : predicate on the token being composed of only alphanumeric characters
- is stop : predicate on the token being a stop word
- strings are hashed for efficiency, so defaults are integers:
- spacy.explain("…") can be used to fetch short descriptions of tags and labels
- extra tooling : for visualizations see DisplaCy
2.3. Named Entities
- a named real world object…
- person, country, product, book title, etc..
- a doc object is an iterable of tokens by default
- an iterable of entities can be fetched via
doc.ents:
import spacy # downloading and loading the languge object nlp = spacy.load("en_core_web_sm") # creating the document object doc = nlp("the quick brown fox jumped over the lazy dog") for ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
- again, the DisplaCy visualizer
- for a theoretical outlook, see Named Entity Recognition (NER)
2.4. Word Vectors (embeddings) and Similarity
- see Text Representation and specifically text-embeddings
- note that small trained pipelines like "en\core\web\sm" (ending in "sm") don't ship with word-vectors
- instead, use the variant ending in "lg" : "en\core\web\lg"
- given the pipeline ships with vectors, normal objects like
token,docandspannow have avectorattribute that defaults to the average of their token vectors.
import spacy nlp = spacy.load("en_core_web_lg") doc = nlp("the quick brown fox jumps over the lazy dog") # do note that this (comments in a paren block) is invalid python code for token in doc: print(token.text, \ # original token text token.has_vector, \ # predicate on if this token has a vector representation token.vector_norm, \ # L2 norm of the token's vector token.is_oov) # predicate for whether the token is out of vocabulary
- now that token and token spans can be mapped to vectors, a notion of similarity arises ( see cosine similarity for a quick approach )
- every
Doc,Span,Token,Lexemehas a.similarityattribute. - note that non-singular spans have their vectors as the average of their constituent tokens.
import spacy nlp = spacy.load("en_web_core_lg") doc1 = nlp("the quick brown fox jumps over the lazy dog") doc2 = nlp("a lazy dog shouldn't be able jump over a quick brown fox") # similarity b/w documents print(doc1, "<->" doc2, doc1.similarity(doc2)) # similarity b/w tokens and spans lazy_dog = doc2[1:3] fox = doc1[3] print(lazy_dog, "<->", fox, lazy_dog.similarity(fox))
2.4.1. Caveats with .similarity
- vectors are averages of consitutuents :- that isn't necessarily a smart approach
- averaging does not retain the order of words :
The butler killed the jokerandthe joker killed the butlerwill be represented with the same vector -> this probably definitely isn't what we want
- similarity ulimately relies on the embeddings of the tokens that are dependent on the corpus from which these were obtained. Domain specific applications might require a special treatment over the usual similarity pipeline : for instance :
- apple and microsoft
- apples and oranges
- for a more sensible approach to similarity than the vanilla one used in spacy, see sense2vec
- for loading custom word vectors, see https://spacy.io/usage/linguistic-features#vectors-similarity
2.5. Pipelines
When calling a Language object (named as nlp) on a text, post tokenization, the token sequence is pushed through various steps, collectively referable as a processing pipeline.

2.5.1. Details
| Name | Component | Creates | Description |
|---|---|---|---|
| tokenizer | Tokenizer |
Doc |
tokenizes.. |
| tagger | Tagger |
Token.tag |
assign POS tags |
| parser | DependencyParser |
Token.head, Token.dep, Doc.sents, Doc.noun_chunks |
assign dependency labels |
| NER | EntityRecognizer |
Doc.ents, Token.ent_iob, Token.ent_type |
identify and label named entities |
| lemmatizer | Lemmatizer |
Token.lemma |
assign lexemes |
| textcat | TextCategorizer |
Doc.cats |
assign doc level labels |
| custom | see custom components | (Doc,Token,Span)._.<custom_attributes> |
assign custom stuff… |
2.5.2. Configuration
- Each pipeline needs to be configured dependent on what task(s) it wishes to tend to
- this is done via the config
[nlp] pipeline = ["tok2vec", "tagger", ["parser"], "ner"]
- the ordering of the components does matter if they share context for their outputs.
- this isn't the case most of the time. see embedding layers for more info
2.5.3. Further usage and customization
2.6. Architecture
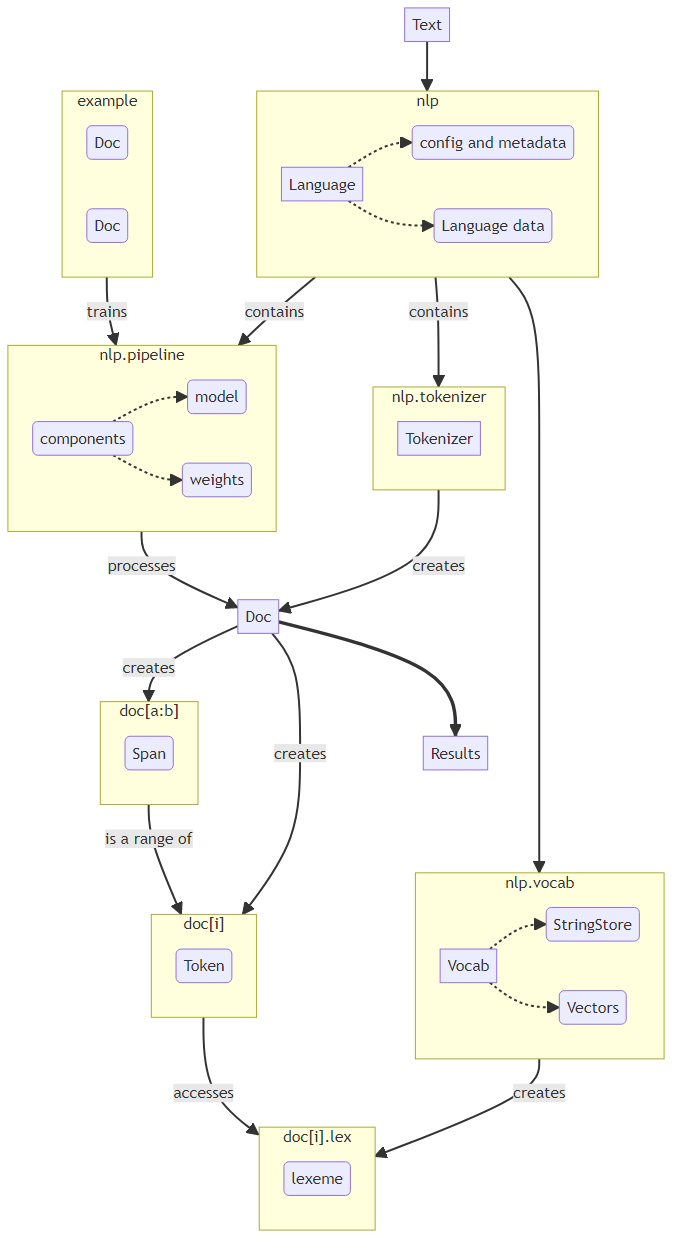
briefly explaining the above flow:
- text is input into a language object
- the language object consists of the tokenizer and the pipeline
- the tokenizer creates the Doc object and tokenizes the text
- the pipeline (with trained components from other doc objects (examples)) then processes the doc object accordingly
- an example is a collection of two doc objects (reference data and predictions)
- all through out, to avoid duplication of strings, we have a vocab that maintains a store of lexemes for the text.
- these are referred to by the tokens and spans in the doc object.
- post processing, the relevant results are extracted from the Doc object
2.6.1. Container objects
The major nodes in the flowchart above are referred to as container objects. here is a brief description
| Name | Description |
|---|---|
| Doc | the main parent contianer to access linguistic annotations |
| DocBin | a collection of Doc objects for efficient binary serialization |
| Example | a pair of two Doc objects: reference data and predictions |
| Language | (tokenizer + pipeline) that transforms text into Doc objects |
| Lexeme | an entry in the vocab. without any context. independent datum. |
| Span | a slice of tokens from the Doc object |
| SpanGroup | a named collection of spans in a Doc |
| Token | an atom in the vocab (word, punctuation, whitespace, etc.) |
2.6.2. Processing Pipelines
- collation of multiple pipeline components that are called in order in the Doc object.
- the tokenizer is separate from this and is run before them all
- a pipeline can be added via
Language.add_pipeby supplying the statistical model and/or trained weights. Alternatively, supplying rule-based modifications to the Doc is also possible. - what follows is an overview of some components that can be added via spaCy
| Name | Description |
|---|---|
| AttributeRuler | set token attributes using matcher rules |
| DependencyParser | predict synctactic dependencies |
| EditTreeLemmatizer | predict base forms of the tokens |
| EntityLinker | disambiguation for named entities (into nodes) in a knowledge base |
| EntityRecognizer | predict named entities |
| EntityRuler | add entity spans to the doc using token based rules or extract phrase matches |
| Lemmatizer | determine base forms using rules and lookups |
| Morphologizer | predict morphological features and coarse-grained POS tags |
| SentenceRecognizer | predict sentence boundaries |
| Sentencizer | implement rule-based sentence boundary detection, without the DependencyParser |
| Tagger | predict POS tags |
| TextCategorizer | predict categories and labels over the whole documnent |
| Tok2Vec | apply a token to vector model and set its outputs |
| TrainablePipe | base class from which all trainable pipeline components inherit |
| Transformer | use a transformer and set its outputs |
| other functions | apply custom functions to Doc in a pipeline :- convenience and uniformity of processing |
2.6.3. Matchers
Pattern matching for Doc objects :- used to find and extract information. They operate on Docs, yielding access to matched tokens in context.
| Name | Description |
|---|---|
| DependencyMatcher | match sequences based on dependency trees using SemGrexPattern |
| Matcher | match sequences of tokens, based on pattern rules, similar to regex |
| PhraseMatcher | match sequences of tokens based on phrases |
2.6.4. Misc
checkout other relevant classes in other classes
2.7. Vocabs, Hashes and Lexemes
- The default preference is to have a single storage of a unique token in the vocab where it is referred to by multiple documents.
- strings are encoded to hash values
- this also applies to meta-data (tag-strings like "VERB" or "ORG" (entity type)) :- they're also hashed
- All internal communication (for the spaCy lib) is carried out via hashes
2.7.1. Summarizing Relevant Lingo
| Object | Description |
|---|---|
| Token | word, punctuation, etc in context (includes attributes, tags and dependencies |
| Lexeme | word type, without context (includes word shape and flags (for data type (lowercase, digit, etc))) |
| Doc | a processed containement of tokens (therefore, also carries context) |
| Vocab | a collection of lexemes |
| StringStore | a bidirectional mapping b/w hashes and strings |
Do note the storage units in the flowchart below with their internal maps
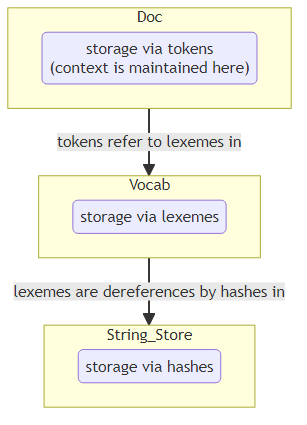
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("I don't drink coffee") print(doc.vocab.strings["coffee"]) # 3197928453018144401 print(doc.vocab.strings[3197928453018144401]) # 'coffee'
Note that the same attribute of vocab is referred to lookup strings and hashes.
The only point of maintaining context is the doc object via relations between tokens.
2.7.2. Attributes of a Lexeme
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("I don't drink coffee") for word in doc: lexeme = doc.vocab[word.text] print(lexeme.text, # original text lexeme.orth, # hash value lexeme.shape_, # abstract word shape lexeme.prefix_, # default - first letter of word string lexeme.suffix_, # default - last three letters of word string lexeme.is_alpha, # predicate on existence of alphabetic characters lexeme.is_digit, # predicate on existence of digits lexeme.is_title, # predicate on the lexeme being in title case lexeme.lang_) # language of the lexeme
2.8. Serialization
- to save stuff, see Serialization
- spacy offers inbuilt functionality for the same, via pickle
- pretty convenient, check dill for advanced functionalities
- All container classes (Language, Doc, Vocab, StringStore) expose this functionality via the following
| Method | returns | instance |
|---|---|---|
| .to/bytes | bytes | data = nlp.to/bytes() |
| .from/bytes | object | nlp.from/bytes(data) |
| .to/disk | - | nlp.to/disk("path") |
| .from/disk | object | nlp.from/disk("path") |
read more on saving and loading here
2.9. Training
- most pipeline components that spacy uses are statistical (weight based).
- rule based pipes can also be incorporated but not focusing on that right now
- these weights are decided upon post training that model
- that requires training data (pairs of text instances and corresponding labels)
- on generic details for training various components, see Text Representation and Information Extraction
- A generic treaty on training models is explored in the node : Training Loop
- for specific info on how to train models in spacy, see this page
2.10. Language data
- shared and specific language data are stored in their respective directories when working with multiple languages
- some relevant lingo to this store is as follows
| Name | Desc. |
|---|---|
| Stop words (stop/words.py) | list of most common words in a language that one would benefit from when filtered out |
| Tokenizer exceptions (tokenizer/exceptions.py) | special-case rules for tokenization (contractions and abbreviations for instance..) |
| Punctuation rules (punctuation.py) | regex for splitting tokens (for punctuations, prefixes, suffixes, and infixes) |
| Character classes (char/classes.py) | character set to be used in regex |
| Lexical attributes (lex/attrs.py) | custom functions to add lexical info ("like/num" for instance to detect "seven", "ten", etc) |
| Syntax iterators (syntax/iterators.py) | functions to compute views of a Doc object based on syntax. used only for noun-chunks as of now |
| Lemmatizer (lemmatizer.py, spacy-lookups-data) | custom lemmatizer implementation and lemmatization tables |
3. Conclusion
- this should serve as a quick index into what spacy can be used for and how.
- it also houses relevant links to internal and external nodes that may be used to explore the same with greater depth.
- further objectives include some practical exploration and populating Advanced NLP with spaCy simultaneously