Information Extraction
Table of Contents
1. Misc
- extracting relevant information (structured query-response pair) from a given text (unstructured data)
- is a relatively complex task than classification and requires further preprocessing/more complicated representations (part of speech tagging for instance) than just getting away with treating text as tokens.
- a different pipeline may need to be employed dependent on how the knowledge base is structured - queryable knowledge bases have to be treated differently than a collection of documents without much metadata.
2. Applications
- Tagging news and other content -> topic recognization by search engines for quick displays.
- Chatbots -> understanding references to entities in a conversation, and understanding their nature (location, person, etc) to be able to respond appropriately.
- Social media monitoring : evolution of an event related to specific topic aka crowd sourcing potential news.
- processing structured documents (forms and receipts) : OCR + NLP
3. Tasks in IE
The simpler ones can be categorized into the below. Complex combinations of the following/spinoffs thereoff will be explored in dedicated nodes.
3.1. Key Phrase Extraction (KPE)
3.1.1. Misc
- representing the gist of the text with concise phrases
- can be use for searching, summarizing, tagging…
- tackled with both supervised and unsupervised learning
3.1.2. Approach
- in most unsupervised approaches : phrases/words are represented by nodes in a graph with weights signifying their importance. Keyphrases are then identified by analysing their connected with the rest of the graph. The algorithm may then report top-n such nodes.
- choosing what phrases form the nodes is a source of another degree of freedom when implementing the algorithms.
- see Textacy (built upon Spacy)-> implements TextRank and SGRank
- see genism -> implements TextRank
- Practical
- naive usage of the graph based algorithms will be too slow for large documents in production and requires some hard coded intelligence to deal with such cases (eg: checking for key phrases only at the top and bottom of the document (one would expect the introduction/conclusion to be a good representation of the documents intent))
- post processing is necessary for noise-free results (prepositions, subsets of other results, etc).
- The algorithm may be explicitly tweaked as another way to deal with the above problem.
3.2. Named Entity Recognition (NER)
3.2.1. Misc
- identifying named entities in a document without explicitly given info for the same -> "where was Anakin Skywalker born?".
- The algorithm has to figure out that Anakin is a fictitious character, and extract the name of the ficitious place where he was born (Tatooine).
- entities can be names of persons, locations, organizations … context specific strings like monetary figures, law numbers etc.
- NER is also a major precursor to the tasks that follow in this buffer
3.2.2. Approaches
- straight-forward way -> maintain a large collection of type-entity pairs -> termed as a gazetteer. The problem is reduced to that of a lookup : this is a good starting point if the collection is large.
- basically turns into the maintenance of a data structure (search, insert, deletion etc..) and choosing a representation for specific cases (aliases, for instance)
- The next step is rule-based NER -> operates by storing common patterns based on word tokens and part of speech tagging. see Named Entity Recognition | CoreNLP and SpaCy's EntityRuler � spaCy API Documentation
- Practically, ML models are preferable over hard-coded intelligence.
- a decision has to be made for each word for whether it is an entity (similar to a Text Classification problem for each word -> a sequence annotation/labelling problem -> context is important for each word and one can't classify them independently -> first and last names for instance, or words only indistinguishable via context (river bank, investment bank)).
- architecturally speaking, Conditional Random Fields are popular sequence classifier choices.
- exploring Sequence Classification completely in another node.
3.3. Named Entity Disambiguation and Linking (NED and NEL)
3.3.1. Misc
- consider : "Lincoln drives a lincoln aviator and lives on lincoln way"
- all three mentions of lincoln are different and should be tagged to different entities -> say their wikipedia pages
- also relies on context like NER.
- might also need coreference resolution to resolve and link multiple references to the same entity. (eg: intial full-name, pronouns, titles, etc for a human referred in multiple ways in a passage)
- NEL is a prerequisite for further tasks in the NLP pipeline as shown in the flowchart below in this buffer
3.3.2. Approaches
- is typically modelled as a supervised ML problem and evaluated in terms of Classification Evaluation Metrics like precision, recall and f1-scores.
- off-the-shelf APIs are the way to go if specialized domains aren't needed and one doesn't wish to develop an inhouse solution.
- when incorporating in existing solutions, domain specific oddities won't be captured when using readily available services
3.4. Relation Extraction
3.4.1. Misc
- NEL will be a prerequisite to Relation Extraction
- objective is to produce 3-tuples in the format of
(entity 1, relationship tag, entity 2): for instance(Steve Jobs, Former CEO, Apple Inc)is potentially useful relation that could be extracted from the (corpus for the task) book "Steve Jobs by Walter Isaacson". - it's an important step towards building a knowledge base which can further be employed to improve search and solve question-answering tasks.
3.4.2. Approaches
- handwritten patterns (regex) are a basic start
- accurate when the format is known for sure but won't be able to cover all kinds of relations within a generic corpus
- from an ML perspective : Relation extraction can be formulated as supervised classification problem. The dataset is a collection of predefined relations, similar to classification categories.
- the task is then reduced to identifying if (binary classification) and how(multiclass classification) two entities are related.
- see Distant Supervision
- Unsupervised Relation extraction (aka open IE) aims to extract relations without relying on existing training data or a list of relations: the relations may be in the form of
(verb, argument 1, argument 2,...).- for instance :-
(published, Albert Einstein, The theory of relativity, in 1915)-> this can be further broken down into 3 relations with only two of the arguments in each.
- for instance :-
- again, off-the-shelf APIs are preferred if a domain specific solution isn't needed -> see Watson API for RE
3.5. Temporal Information Extraction
- extracting date and time info from text
- converting to a standard format for further use (calendars, meet schedulers, etc)
- referred as "Temporal IE and normalization" altogether
- see library : python Duckling
3.6. Event Extraction
- treated as a supervised learning problem in NLP literature.
- contemporary approaches use sequence tagging and multilevel classifiers.
- identify events over time, chain them, link them and so on ..
3.7. Template Filling
- extracting entities from a common template the occurs several times
- Linking entities to build an an entity graph
- templates to be filled are pre-determined
- modelled as two stage, supervised task (similar to relation extraction)
- is a template present in a given sentence?
- what are the candidates for that template in that sentence?
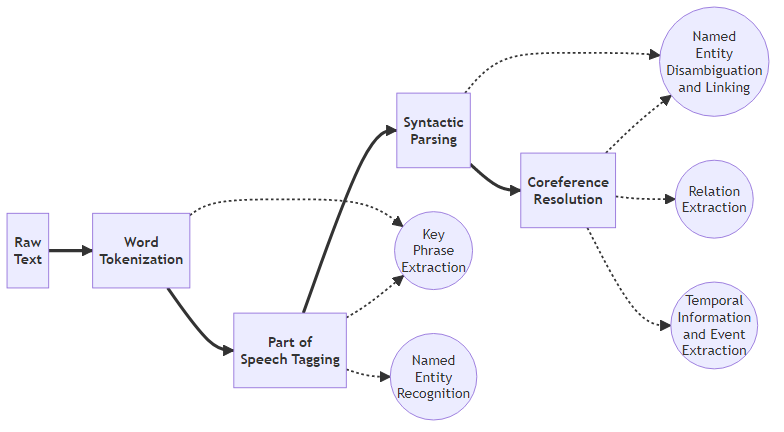
4. Generic IE Pipeline
Numeric bullets signify a step in the pipeline and indents signify what task they contribute to. This will be directed and acyclic.
- Raw text
- Word Tokenization -> Key Phrase Extraction (KPE)
- Part of Speech Tagging -> Key Phrase Extraction (KPE) -> Named Entity Recognition (NER)
- Syntactic Parsing -> Named Entity Disambiguation and Linking
Coreference Resolution -> Named Entity Disambiguation and Linking -> Relation Extraction -> Temporal Information Extraction (events/durations)