Data Engineering
Table of Contents
1. Core Nodes
1.1. Data Engineering Lifecycle
1.1.1. Overview
- Overall Flow
@startuml frame { [Storage] } frame Processing { [Ingestion] -right-> [Transformation] [Transformation] -right-> [Serving] [Storage] -up-> [Ingestion] [Storage] -up-> [Transformation] [Storage] -up-> [Serving] } [Generation] -down-> [Processing] frame Applications { [Analytics] [Machine Learning] [Reverse ETL] } Serving =right=> Applications @enduml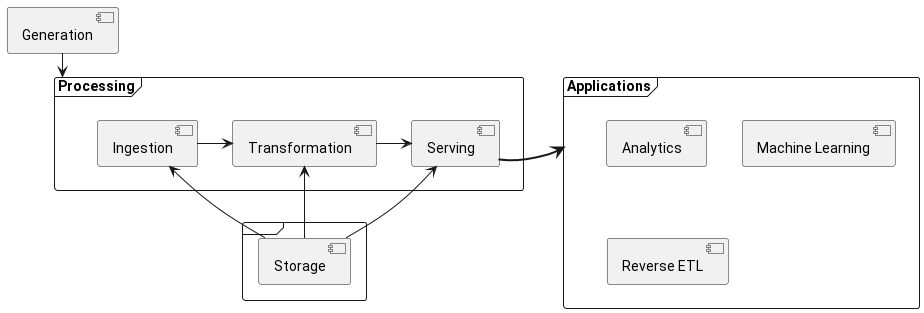
- Generation
- source systems : origins of data in the lifecycle
- possibilities:
- IoT device
- application message queue
- transactional database
- the data engineer consumes from the source systems but doesn't own them
- practical examples:
- application database
- IoT swarms
- Storage
- data architectures leverage several storage solutions for all kinds of flows, stores and transitions
- they also need to have side-car processing capabilities to serve complex queries
- storage is omnipresent across the cycle from ingestion to serving results and the transformations sandwiched within
- streaming frameworks like apache kafka and pulsar can simultaneously function as ingestion, storage and query systems for messages
- Ingestion
- Transformation
In the data engineering lifecycle, the transformation process is a critical stage where raw data is converted into a suitable format for analysis and utilization. Here are the key aspects of the transformation process:
- Extraction:
- Raw data is sourced from multiple origins, including databases, external data feeds, sensors, and more.
- Data Cleaning:
- Removing duplicates, correcting errors, and filling in missing values to ensure data quality.
- Standardizing data formats and naming conventions for consistency.
- Data Integration:
- Combining data from different sources to provide a unified view.
- Resolving heterogeneities and conflicts in data schemas.
- Data Transformation:
- Changing data from its original form into a format that is analyzable. This includes:
- Normalization/Denormalization: Adjusting the data structure for better access or storage.
- Aggregation: Summarizing data to provide insights at a higher level.
- Enrichment: Adding new data fields derived from existing data to enhance context.
- Changing data from its original form into a format that is analyzable. This includes:
- Filtering:
- Removing unnecessary or irrelevant data to focus on what's important.
- Feature Engineering:
- Creating new variables or modifying existing ones to improve the performance of models.
- Validation:
- Ensuring that transformed data meets quality and integrity standards.
- Conducting checks against business rules and expectations.
- Connections and Importance:
- The transformation process is intrinsically connected to subsequent stages of data analytics and machine learning, as the quality and structure of transformed data directly impact the performance of analytics models.
- It ensures that data is suitable for storage in a data warehouse or data lake, where further data exploration can occur.
- By transforming data appropriately, businesses can derive actionable insights that drive strategic decisions.
- Extraction:
- Serving
- Analytics
- MultiTenancy
- Machine Learning
- Reverse ETL
1.1.2. Undercurrents
- Security
- Access Control for:
- Data
- Systems
- The Principle of Least Privilege
- Access Control for:
- Data Management
- Data Governance
- Discoverability
- Definitions
- Accountability
- Data Modeling
- Data Integrity
- Data Governance
- DataOps
- Data Governance
- Observability and Monitoring
- Incident Reporting
- Data Architecture
- Analyse tradeoffs
- Design for agility
- Add value to the business
- Orchestration
- Coordinate workflows
- Schedule jobs
- Manage tasks
- Software Engineering
- Programming and coding skills
- Software Design Patterns
- Testing and Debugging
1.1.3. The Data Life Cycle
- The Data engineering lifecycle is a subset of the data life cycle (explored separately)